使用半监督学习从研究到产品化的3个教训( 五 )
如果类平衡对SSL在实践中的成功至关重要 , 那么我们如何在半监督的物体检测中实现类平衡呢?未来解决这一问题的研究肯定会受到欢迎 。
其他的一些Tips迁移学习和自训练叠加
正如在Zoph et al., 2020中对COCO训练发现的那样 , 从COCO到我们的数据集执行转移学习 , 然后在Noisy Student中进行自训练 , 取得的结果比单独执行两个步骤中的任何一个都要好 。 应用于生产模型的任何迁移知识很可能也可以应用于SSL模型 , 带来同等或更多的好处 。
适当的数据增强很重要
由于数据增强是现代SSL方法的主要组成部分 , 所以要确保这些增强对你的领域有意义 。 例如 , 如果可用的扩展集包括水平翻转 , 那么训练用于区分左箭头和右箭头的边框的分类器显然会受到影响 。
此外 , 在STAC和Noisy Student中 , 他们观察到 , 在自训练中 , 对教师模型使用数据增强会导致较差的下游学生模型 。
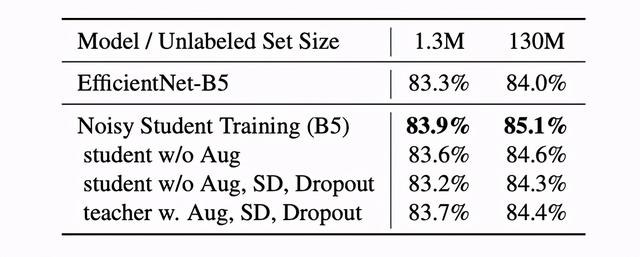 文章插图
文章插图
表6来自Xie et al., 2019 。 在这项消融研究中 , 他们表明 , 有增强的教师模型比没有增强的教师模型表现略差(在130M未标记图像上 , 分别为84.4%和85.1%) 。
然而 , 我们发现 , 在我们的数据集上 , 使用数据增强的教师模型的Noisy Student和STAC的性能与不使用增强的教师模型相当或略好 。 虽然我们的结果可能是我们自己的数据集的一个特例 , 但我们相信这显示了广泛实验的重要性 , 并对你在论文中读到的观点的所谓成功和失败保持好奇 。 论文中显示的实证结果是一个很好的开始 , 但成功肯定是不能保证的 , 在SSL中仍有许多从理论角度尚不清楚的理解 。
临别赠言在过去的一年里 , 半监督学习(SSL)是我们工作的一个令人兴奋的领域 , 它在我们的生产模型中的最终结果向我们(也希望你们所有人)表明 , 在某些情况下可以而且应该考虑SSL 。
特别是在Noisy Student中进行自训练 , 对于改进我们的目标检测模型是有效的 。 以下是我们在研究和生产深层SSL技术时所学到的3个主要教训:
- 简单为王
- 使用启发式的伪标签优化是非常有效的
- 半监督图像分类的进展很难转化为目标检测
英文原文:@nairvarun18/from-research-to-production-with-deep-semi-supervised-learning-7caaedc39093
更多内容 , 请关注微信公众号“AI公园” 。
- 不看不知道 80%的人使用耳机的习惯都错了
- 研究发现许多iOS加密措施实际上未被使用
- 雷蛇RGB口罩真的来了!N95级别可重复使用
- 学习了大数据开发知识,但是面试却屡屡碰壁该怎么办
- 大一上学期学了Python,希望主攻大数据还应该学习什么语言
- 大一下学期转入计算机专业,寒假期间该重点学习什么内容
- Android 12或让未使用的App休眠以节省系统资源
- iOS 14.4版开始将对使用非原装摄像头的iPhone弹出警告
- 从运维岗转向开发岗,该选择学习Java还是Python
- 想学习编程,该从哪开始