使用半监督学习从研究到产品化的3个教训( 二 )
在这种情况下 , 我们要强调的是 , 得到具有生产价值的性能的可能性较低 —— 但是对于没有标记数据的任务 , 如果有一个数量级或更多的未标记数据 , 并且有足够的激励、时间和资源 , 那么尝试使用SSL是有意义的 。
- 你正在处理的问题是 , 仅使用已标记的数据就足以产生足够的性能 , 但是你有一个未标记的样本集合 , 希望进一步提高性能 。
 文章插图
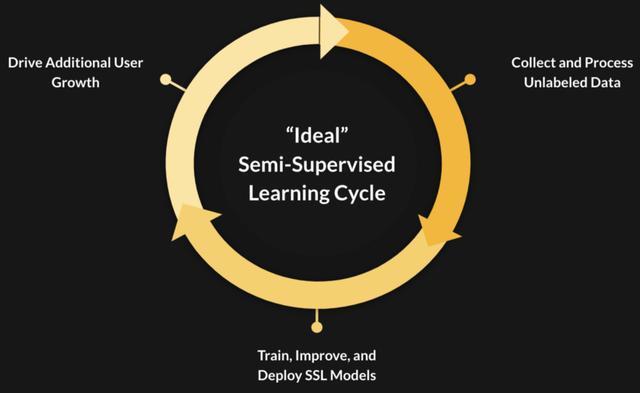
文章插图【使用半监督学习从研究到产品化的3个教训】生产环境中的半监督学习(SSL)模型的生命周期 , 在这种环境中 , 不断增长的用户群可以创建一个正向的反馈循环 。
SSL方法的研究这里有一些方法我们在下面的图像分类和目标检测中尝试过 , 但SSL还可以适用于其他领域如NLP以及音频/语音处理 。
图像分类
- MixMatch (Berthelot et al., 2019)
- Unsupervised Data Augmentation (UDA) (Xie et al., 2019)
- FixMatch (Sohn et al., 2020-A)
- CSD (Jeong et al., 2020)
- STAC (Sohn et al., 2020-B)
- Noisy Student (Xie et al., 2019)
然而 , 经验上我们这样做并不是最优的 , 主要是因为 ——hyper-parameter调优 。 许多在论文中用于数据集的超参数的用在我们数据集上变得对性能很敏感 。 我们也注意到 , 我们的标签数据集在无标签数据上分布稍微有点不同 , 这个问题通常会导致SSL技术性能下降 , 这是在现实中使用SSL需要克服的一个挑战 。 截至2019年9月 , 对于我们来说 , 现有的最先进的SSL技术似乎还不够简单或灵活 。
快进到2020年6月 , 两项新的SSL工作已经发布 , 它们专注于简单的实现 —— FixMatch和Self-Training with Noisy Student 。
 文章插图
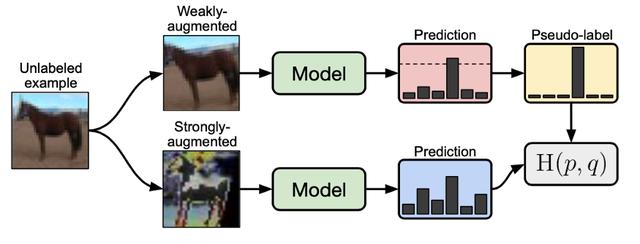
文章插图未标记图像如何在FixMatch中使用(Sohn et al. ,2020) 。
FixMatch是其前身MixMatch的一个更简单但更有效的版本 , 我们成功地将他们的结果在CIFAR10, SVHN上复现了 。 这一次 , 我们在自己的图像分类数据集上也看到了很好的结果 , 性能对超参数的选择不那么敏感 , 而且可以调优的超参数也很少 。
 文章插图
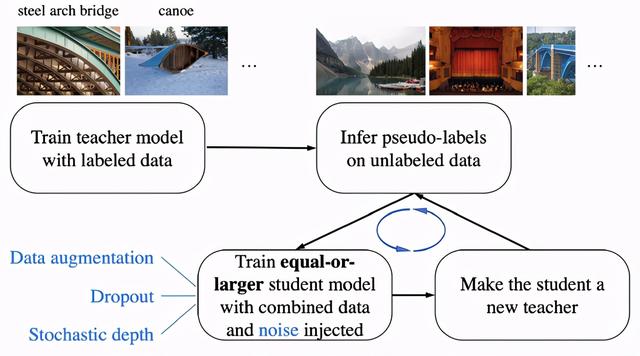
文章插图Self-Training with Noisy Student (from Xie et al., 2019)的图解
Noisy Student 训练包括一个迭代过程 , 在这个过程中 , 我们训练一个教师模型(可以访问标记数据的模型) , 使用这个模型推断未标记数据的输出 , 然后在标记数据和伪标记数据上重新训练一个称为学生的新模型 。 然后我们可以重复这个循环 , 即所谓的self-training , 通过这个学生模型在未标记集上推断新的伪标签 。 论文中展示了使用这个框架在300M未标记图像中进行了训练 , 并强调了添加各种类型的噪声(增强 , dropout等)是成功的关键 。
- 不看不知道 80%的人使用耳机的习惯都错了
- 研究发现许多iOS加密措施实际上未被使用
- 雷蛇RGB口罩真的来了!N95级别可重复使用
- 学习了大数据开发知识,但是面试却屡屡碰壁该怎么办
- 大一上学期学了Python,希望主攻大数据还应该学习什么语言
- 大一下学期转入计算机专业,寒假期间该重点学习什么内容
- Android 12或让未使用的App休眠以节省系统资源
- iOS 14.4版开始将对使用非原装摄像头的iPhone弹出警告
- 从运维岗转向开发岗,该选择学习Java还是Python
- 想学习编程,该从哪开始