DeepMind秀出最强游戏AI!57场Atari游戏超过人类,复盘游戏AI进化史( 二 )
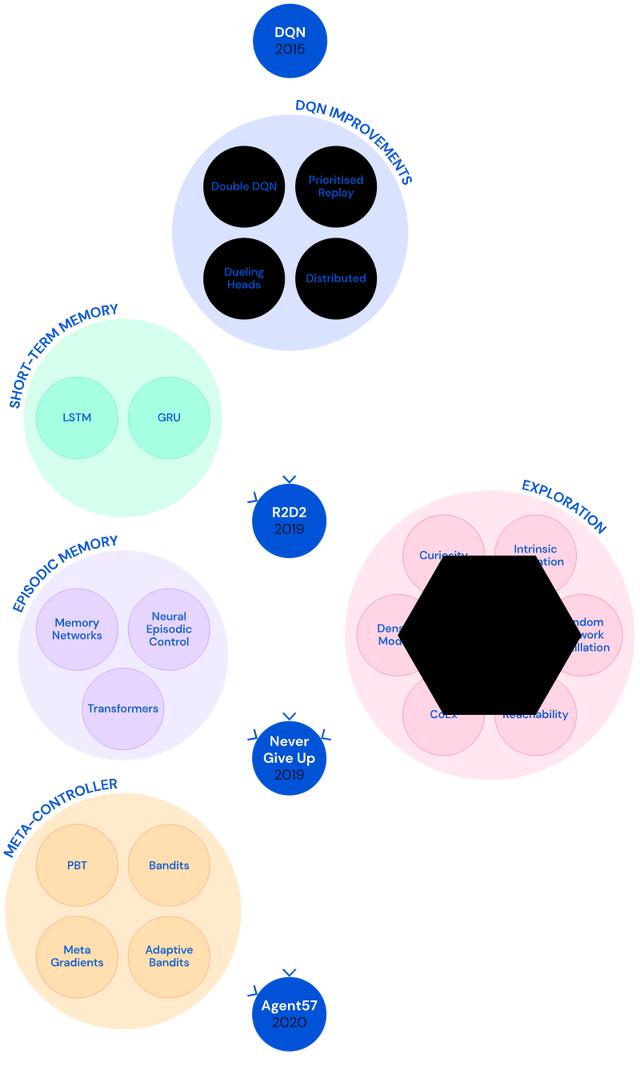
二、智能代理迭代发展为解决这些问题 , DeepMind进行了长期探索 , 开发了几代模型 。
 文章插图
文章插图
1、初始版本:智能代理DQN
在2015年 , DeepMind开发了DNQ算法代理(Deep Q-network agent) , 这是第一个能在大多数Atari57游戏中达到人类基准的算法 。
测试时 , DQN在两类游戏中表现不佳 。
一种以《索拉里斯(Solaris)》、《滑雪(Skiiing)》为代表 。 这类游戏的规则是要求代理尽可能快地通过所有游戏关卡 , 游戏奖励与通关时间成正比 。 每错过一个门 , 通关就会被延迟5秒钟 。 在游戏早期 , 代理要经过长期的学习来理解“错过了门”这一行为与“通关延迟”间的关系 。
另一种以《蒙特祖马的复仇(Montezuma’s Revenge)》、《陷阱(Pitfall)》为代表 , 是探索类游戏 。 在这类游戏中 , 代理要进行大量的尝试(可能是数百个动作)才能通过关卡 。
在这两种游戏中 , DQN普遍得分较低 。 为了解决这一问题 , 研究人员做了一些改进 。
2、R2D2:深度分布式RL代理+短期记忆+异策略学习
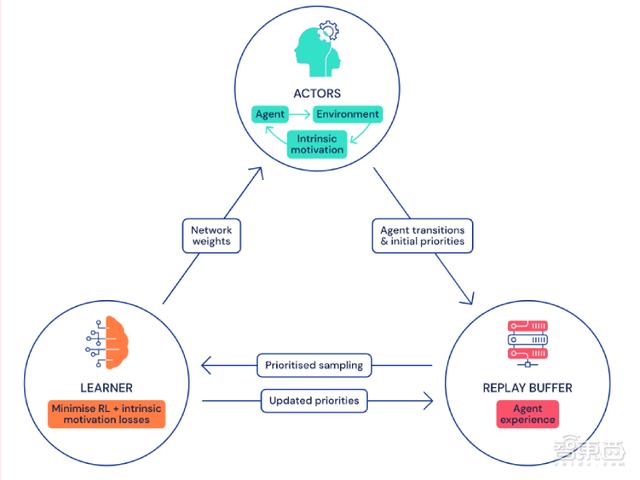
所谓“分布式” , 就是将数据收集与学习过程分开 。 研究人员综合了DQN、Gorila DQN、ApeX三种智能代理的特点 , 设计出了深度分布式代理模型 。 它可以在多台计算机上运行、运行速度更快 。
actor从环境中收集到数据后 , 将其以优先重放缓存的形式存储到中央“内存库” 。 然后 , learner会从重放缓存中提取数据 , 用于训练 。
接下来 , 神经网络会以损失最小化的方式来更新参数 。 最后 , 每个参与者与学习者共享同一个网络架构 , 但保留自己的权重副本 。
learner的权重会经常发送给actor , 以让actor根据优先级更新自己的权重 。
 文章插图
文章插图
在代理处理任务时 , 不仅要能留意到当下的情况 , 还要能借鉴之前的结果 。 就是说 , 代理需要有“记忆力” 。
举例来说 , 假如代理从一个房间走进另一个房间 , 计算每个房间中椅子的数量 。 如果没有记忆 , 代理需要数两次数目 。 但如果有记忆 , 代理只需用第一个房间中的椅子数加或减去差值 , 就可以计算出第二个房间中的椅子数 。
在深度强化学习中 , 神经循环网络(如长短期记忆网络)被用于实现短期记忆 。
除了拥有记忆以外 , 研究人员希望代理能做到离线学习(Off-policy learning) 。
相比于异策略学习来说 , 它的对立面同策略学习(On-policy learning)更易于实现 。 同策略学习是指代理学习其直接行为造成的后果 。 而Off-policy learning则是代理在没有进行某个行为的前提下 , 推算出该行为可能会导致的后果 。
在Off-policy learning模式下 , 即使采取随机行动 , 代理也有可能找到最佳行动方案 。
第一个结合了记忆能力和Off-policy learning模式的智能代理是深度循环Q网络(Deep Recurrent Q-Network , DRQN) 。
第一个结合了深度分布式结构、记忆能力和Off-policy learning模式的智能代理则是Recurrent Replay Distributed DQN(R2D2) 。
三、NGU(前身):定向探索能力+内在奖励机制DeepMind的第四代智能代理采用情境记忆模式 , 可以判断出当前情况是否曾出现过 , 并优先选择完成新任务 。 这一代智能代理被命名为Never Give Up(NGU) 。
1、探索定向探索能力
研究人员对智能代理探索游戏环境的方式进行了设计 , 首先是采用epsilon-greedy方式 。
使智能代理按照固定概率 , 采取一个随机动作 , 如果不能继续游戏 , 就采取目前为止的最佳动作 。 在epsilon-greedy方法下 , 代理依赖不定向随机的行为选择来发现不可见的状态 , 要花费很多时间 。
- 抢跑上市最强5G芯片系列新机,败走中国的三星让价换销量
- 目前续航能力最强的五款手机,过年回家不怕电不够用
- 神思电子入选AI中国·最强人工智能公司TOP30
- 中国最强芯片巨头,一年花1098亿,2022年量产3nm芯片
- DeepMind巨亏42亿、独角兽惨遭3折贱卖,AI公司为何难有“好下场”?
- 三星最强5G SoC来了!Galaxy S21首发
- 边缘|边缘计算将取代云计算?5G时代的最强黑马出现了吗?
- 中国影响力最强的企业榜单出炉,马云、马化腾不在列,榜首是雷军
- iPhone 13屏幕曝光:搭载三星最强120Hz屏
- DeepMind新AI无需提前知晓规则也能掌握游戏:无论视觉简单还是复杂